Today’s computer networks produce a huge amount of security log data. The security event correlation scalability has become a major concern for security analysts and IT administrators when considering complex IT infrastructures that need to handle huge amount of security log data. The current correlation capabilities of Security Information and Event Management (SIEM), based on a single node in centralized servers, have proved to be insufficient to process large event streams. Also a network might be highly segmented due to security policies or geographic distribution, mandating specific collection capabilities. Or an organization might be constrained by budget and staffing limitations, requiring an incremental approach to rolling out a deployment. ANET SureLog “Hierarchical Master-Slave Model” manage events in a distributed manner for offloading the processing requirements of the log management system for tasks such as collecting, filtering, normalization, aggregation. This model also is solution for security related issues and incremental approach. The main advantage of “Hierarchical Master-Slave Model” is easily extendable and scalable by adding regional SIEM implementations. This architecture is also good for the big organizations where the log sources are located in multiple data centers and/or regions. This architecture is recommended for global and/or distributed environments where there is a need for high throughputs or customer data are located throughout the world or country.
When to consider “Hierarchical Master-Slave Model”?
• Measured EPS is bigger than 25,000 events/second (This is NOT a peak rate),
• Many separate sites, which are geographically distributed like: US, Europe and Asia; a few datacenters and a few regional offices,
• Log source mix is a diverse blend of firewalls, network devices, NIPS, Windows servers, Unix/Linux servers, web proxies, and also web servers and database servers,
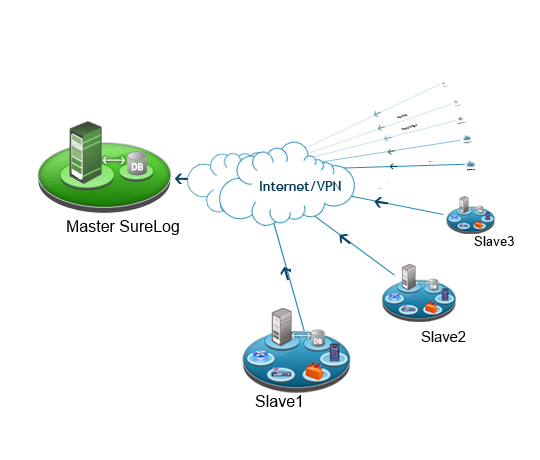
SureLog slaves collect and normalize all the data and send them to SureLog master for correlation. Also master SureLog centralize normalized logs for Log archival and incident investigations.
Slave Functions
• Log collection
• Log filtering before normalization
• Normalization
• Correlation filtering. Filtering unnecessary events for correlation
• Sending logs for correlation, log archival and incident investigations to master
• Short term storage
SureLog Slave advantage includes that it is not just a collector but a log manager.
Master Functions
• Correlation
• Log archival
• Incident
• Long term storage
Cutting-edge Security Information and Event Management (SIEM) Technology
The automated correlation engine in master SureLog process vast quantities of data about an enormous number of events. They also enable analysts to find patterns and to filter, clean, and analyze all that data. Taxonomy of data is at the center of SIEM correlation system. Slave SureLog instances automatically catalogs information by using signatures. Users can further create TAGS of information based upon simple or complex match patterns. Data is cataloged (TAGS) based upon specifications consisting of simple keywords, wildcards and regular expressions, logical expressions of wildcards, definitions of regular expressions. This provides a complete flexibility in managing and grouping message data, while still maintaining high data throughputs.
Role-Based Access
One of the most challenging problems in managing distributed SIEM implementations is the complexity of security administration. Since the roles in an organization are relatively stable, with minimal user turnover and task reassignment, role-based access (RBAC) provides a powerful mechanism for reducing the complexity, cost, and potential for error involved in assigning user permissions within the organization. By using RBAC, a user is limited to a data subset (According to SRC IP, DST IP, Log Source, Username etc..) or SureLog module subset. Limiting by data subset allows the system administrator to create flexible roles that allow users to see only parts of stored data. For instance, roles can be configured so that mail administrators see only mail server data, web administrators see only web server data, etc.
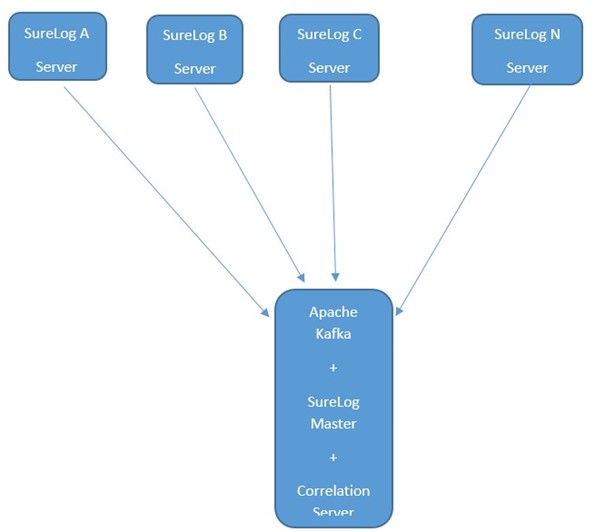
Correlation
For correlation; There are two alternatives. Correlations can be done in SureLog Nodes or they can be centralized using an Apache Kafka server. First, architecturally, SureLog is built on a big data architecture and uses the Apache Kafka ingestion bus to address the scalability issue. The collected events are retained temporarily in Kafka topics in order to allow the data to be shared with the SureLog correlation tier.